Übersicht: Machine learning
Allgemeines
Auf den folgenden Unterseiten finden Sie Informationen zu den Arten von Problemen, die sich mit Hilfe des Machine learning (ML) lösen lassen. Die dazu verwendeten Methoden und die grundlegende Theorie werden kurz umrissen; Codebeispiele detaillieren praktische Anwendungen.
Relevanz
Definition
Im Gegensatz zur mathematischen Optimierung ist die Aufgabe des maschinellen Lernens weniger klar definiert — es beinhaltet nicht nur die Lösung einer Gleichung. Stattdessen beschäftigt sich das ML mit der Entwicklung und Analyse von Algorithmen, deren Leistung mit zunehmender Datenmenge anwächst. Mathematisch gesehen kann dies formalisiert werden als die Minimierung einer loss function (Strafffunktion) \(f_S(x)\) unter Randbedingungen \(D\) für die Parameter \(x\) deren Bestimmung das Ziel des Lernens ist.
Abgrenzung
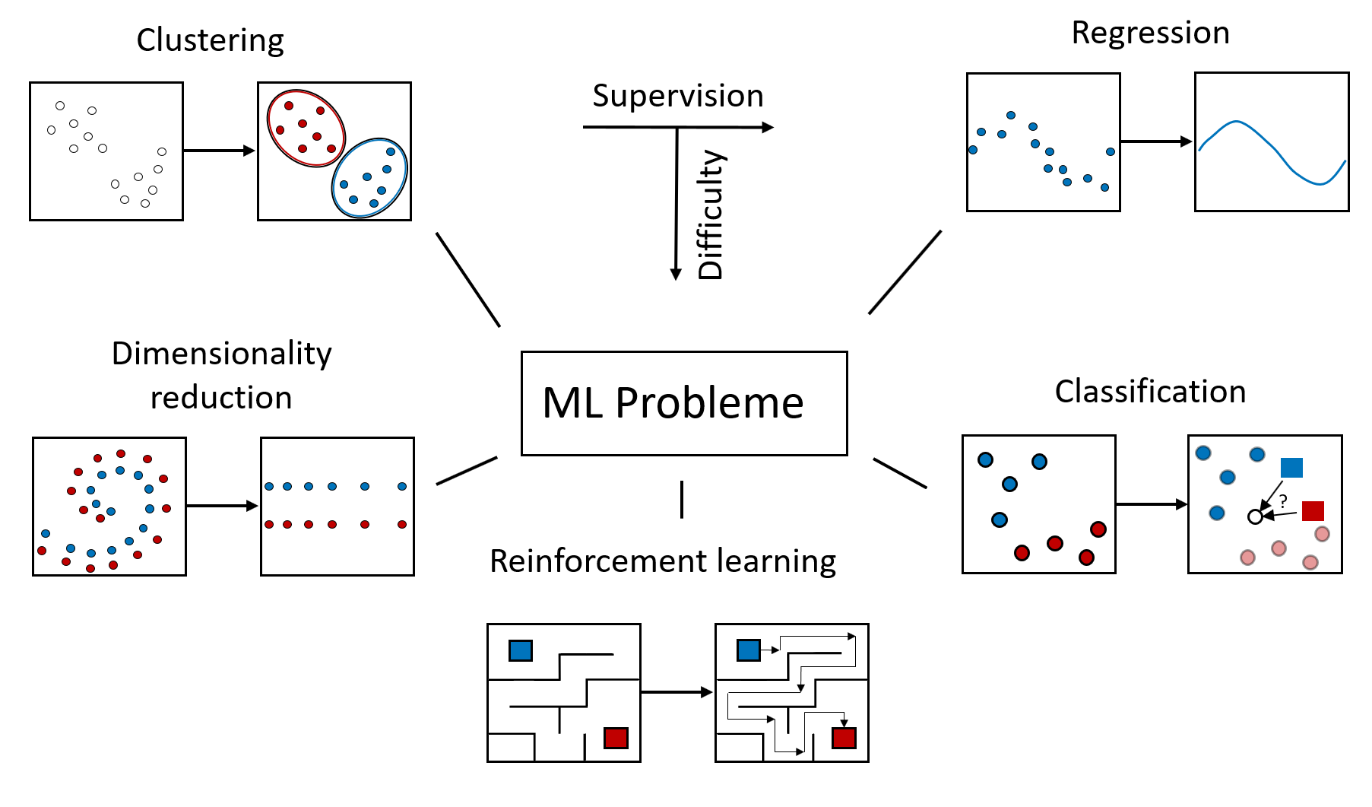
In dieser Hinsicht grenzen sich die Algorithmen des ML ab von klassicher Software, die ein abgeschlossenes System bestehend aus einer fixen Abfolge von Befehlen ist und somit nicht befähigt, die eigene Funktionsweise durch Integration neuer Daten zu verändern. Die Fähgikeit, aus neuen Erfahrungen zu lernen zusammen mit der Ubiquität bestimmter Formen von Daten macht das ML so flexibel, vielseitig einsetzbar aber auch unübersichtlich in der Gesamtheit seiner Methoden. Typischerweise unterscheidet man im ML zwischen drei Aufgabenklassen: Supervised learning Reinforcement learning, Unsupervised learning. Das nachfolgende Bild gibt einen groben Überblick
Beispiele
Je nachdem, welche loss function \(f_S(x)\) gewählt wird, lässt sich ein Algorithmus zur Lösung verschiedenen Aufgaben bewegen: \(f_S(x)\) kann ein Mass sein für Vorhersagefehler, Fehlklassifikationsraten, Strafen für suboptimale Systemsteuerungen, Intra-Gruppen Varianzen, oder Rekonstruktionsfehler. Optimal gewählte Parameter \(x_1,x_2, …\) determinieren das Verhalten des Algorithmus so, dass die loss function (als Mass für die Auswirkungen unerwünschten Verhaltens) möglichst kleine Werte annimmt. Verschiedene Bedeutungen von \(f_S(x)\) und assoziierte Anwendungen sind in der nachfolgenden Tabelle notiert.
| Beispiel | \(f_S(x)\) | \(S\) | \(V(x_1,x_2,…)\) |
|---|---|---|---|
| Preisvorhersage | Vorhersagefehler | Produktfeatures, Preise | Preis |
| Maschinelle Übersetzung | - Satzwahrscheinlichkeit | Paare von Sätzen | Übersetzter Satz |
| Bildklassifikation | Fehlklassifikationsrate | Bilder, Objektklassen | Klassenwahrscheinlichkeiten |
| Krebserkennung | Fehlklassifikationsrate | Medizinische Daten, Diagnosen | Krebswahrscheinlichkeit |
| Maschinensteuerung | Unzielführendes Verhalten | Steuerungsversuche | Steuerungsbefehle |
| Game AI | Wahrscheinlichkeit Niederlage | Spielversuche | Spielstrategie |
| Datenkompression | Rekonstruktionsfehler | Datenbeispiele | Komprimiertes Objekt |
| Betrugserkennung | Verhaltenskonsistenz | Metadaten Transaktionen | Irregularität Transaktion |
Aufgabenfelder
Viele praxisrelevante Aufgaben aus den Disziplinen Finanzwesen, Marketing, Medizin, Bildverarbeitung, Spieltheorie, Datenanalyse, … können als ML Problem \(\min _x f_S(x), x\in D\) formuliert werden. Unabhängig von der konkreten Anwendung identifizieren wir drei Aufgabenklassen, in welche sich Aufgaben aus den obigen Disziplinen einordnen lassen:
Supervised learning
Unter dem supervised learning versteht man ML Aufgaben, bei denen das vom Algorithmus gewünschte Verhalten direkt in Form von Daten vorgegeben werden kann. Insbesondere sind die Regression und Klassifikation. Ein Modell (z.B. ein neuronales Netz) soll dann hinsichtlich seiner Parameter so angepasst werden, dass das Modellverhalten die mustergültigen Daten möglichst genau repräsentiert. Ist das Modell gut gewählt, baut es nicht nurdurch die Daten festgelegt Input- Outputverhältnisse nach, sondern agiert auch plausibel in neuen, nicht von der Datengrundlage abgedeckten Situationen. In diese Aufgabenklasse fallen z.B. die Erstellung von statistischen Modellen, die prädiktive Analytik, die Klassifikation von Text, Audio, Bilder, Videos, Textübersetzung, automatische Generierung von Untertiteln und vieles mehr.

Reinforcement Learning
Unter dem Reinforcement learning ersteht man ML Aufgaben, bei denen es positives und negatives Feedback zur Beurteilung des vom Algorithmus gezeigten Verhaltens gibt. Allerdings gibt es keine direkten Hinweise, welches Verhalten mustergültig und somit zu imitieren ist. Der Algorithmus interagiert mit einem System, das er mit Steuersignalen verändern kann, woraufhin dieses reagiert mit einer Systemänderung und einem bestärkenden oder bestrafenden Feedback. Damit imitiert Reinforcement learning das Lernverhalten in realem und unsicheren Kontext, etwa eines Menschen, der zum ersten Mal Schach spielt. Ziel ist das Ableiten von optimalen Abfolgen von Entscheidungen unter Unsicherheit und in kompetitiven Situationen. In diese Aufgabenklasse fallen unter anderem die optimale Maschinensteuerung, das Anlernen von AI´s in Spielen, aktives Portfoliomanagement, Verkehrsflussleitung Warenlagermanagement und Einkaufsplanung.
Unsupervised learning
Beim unsupervised learning werdem dem Algorithmus keine unmittelbare Vorgaben über das gewünschte Verhalten übermittelt. Muster müssen vom Algorithmus ohne vorherige Lernerfahrung eigenständig in den Daten gefunden werden. Diese werden dann verwendet, um die Daten zu clustern oder auf die wichtigsten Komponenten zu reduzieren. So wird auf einem Datensatz eine Struktur erzeugt, die in der Folge genutzt werden kann, um z.B. atypische Finanztransaktionen zu identifizieren, zusammenhängende Gene zu clustern, ökologisch zusammenhängende Pflanzengemeinschaften zu identifizieren, Recommendersysteme zu betreiben, Märkte in Gruppen zu segementieren, oder soziale Netzwerke zu analysieren.

Aussicht
Die obig genannten Aufgaben sind Standardaufgaben des ML mit eigens für sie entworfenen Algorithmen, die bereits erfolgreich in der Praxis erprobt wurden. Wir stellen nachfolgend einige Beispielprobleme dar und illustrieren deren Lösung mit Code, Sketches, und Beschreibungen. Dabei legen wir Wert auf eine Erklärung des Zusammenhanges zwischen dem Verhalten eines ML Algorithmus´, den loss functions, und den Echtweltimplikationen. In letzter Instanz formalisieren wir wieder Optimierungsprobleme. Im Vergleich zu den Formulierungen in der klassischen mathematischen Optimierung treten hier jedoch datengetriebene nichtlineare Terme wie etwa Kreuzentropien, Kullback-Leibler Divergenzen, und Parameter in neuronalen Netzen auf, die eine zuverlässige Optimierung nicht gestatten. Dies führt zu experimentellen numerischen Verfahren; für neuronale Netze gibt es dennoch gute, öffentlich verfügbare Software wie z.B. Pytorch.
Praktische Anwendungen, Methoden, und Theorie finden Sie in den entsprechend benannten Abschnitten. Wir hoffen, das Material inspiriert Sie bei der Identifikation von oder der Suche nach Anwendungen von Machine learning in Ihrem Betrieb.
